
Choosing the right path for your data can unlock incredible insights. Let’s demystify the main ways machines learn, so you can pick the best approach for your data science journeys.
As I finish up my Master’s in Data Science from Boston University, I want to reflect on what I learn. This is the first post, of who how many, that captures some of what I learned. If you’re just starting in data science or machine learning, you’ve likely heard terms like “supervised learning” or “reinforcement learning” tossed around. But what do they really mean for your projects?
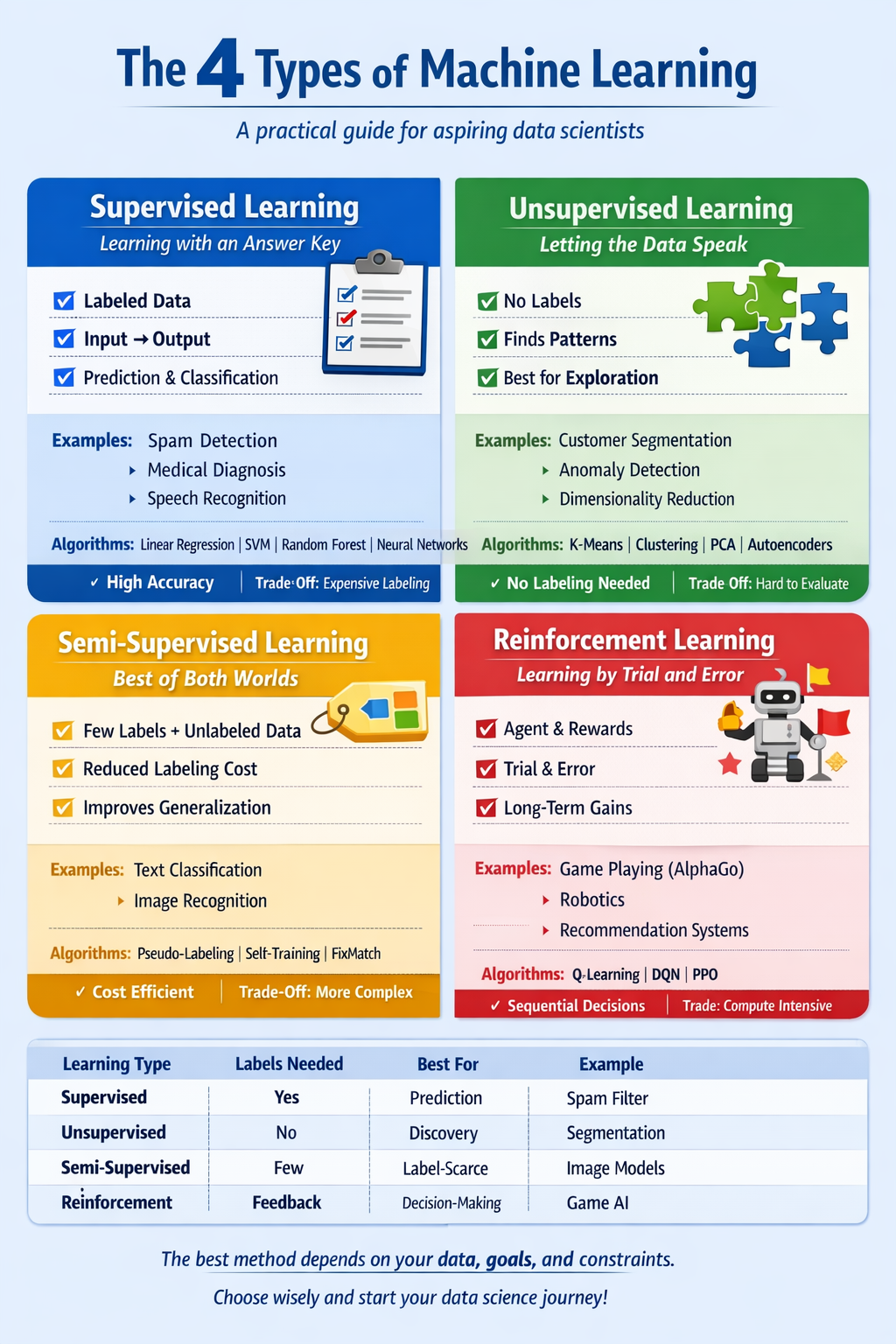
Understanding these four fundamental learning paradigms, supervised, unsupervised, semi-supervised, and reinforcement learning, is a must for anyone hoping to turn raw data into smart, useful systems. Each type has its own strengths, trade-offs, and real-world applications. Picking the right one depends on your data, your goals, and the resources you have.
Let’s break down each type with clear explanations, analogies, and real examples.
1. Supervised Learning: Learning with an Answer Key
Definition:
Supervised learning is like studying with flashcards, the model learns from labeled examples, where each input comes with the correct output. The goal is to generalize from this data so it can predict outputs for new, unseen inputs.
How it Works:
Imagine you want to teach a computer to recognize cats in photos. You show it thousands of images, each clearly marked as “cat” or “not cat.” The computer looks for patterns linking features (like fur, ears, and tails) to the label. Over time, it learns to spot a cat, even in new photos.
Common Examples:
- Spam detection: Email services use labeled emails (“spam” or “not spam”) to train filters.
- Medical diagnosis: Models learn from patient data labeled with diseases.
- Speech recognition: Systems learn how certain audio clips correspond to actual words.
Popular Algorithms:
- Linear regression (for predicting numbers, like house prices)
- Support Vector Machines (SVM)
- Random Forests
- Neural Networks and Deep Learning Models (see BERT for NLP)
Strengths:
- High accuracy on tasks with lots of labeled data.
- Easy to evaluate using metrics like accuracy, precision, and recall.
Weaknesses:
- Needs lots of labeled data, which can be costly to collect.
- Not great for discovering unknown patterns, it only learns what you show it.
2. Unsupervised Learning: Letting the Data Speak
Definition:
Unsupervised learning is like dumping a pile of assorted buttons on a table and figuring out how to group them, without anyone telling you what the groups should be. The model tries to find hidden patterns or structures in unlabeled data.
How it Works:
Suppose you have thousands of customer records but no idea about their behaviors. An unsupervised algorithm can group similar customers (maybe by purchasing habits) without needing any “correct answer” upfront.
Common Examples:
- Customer segmentation: Grouping shoppers with similar buying habits.
- Anomaly detection: Spotting unusual transactions in banking for fraud detection.
- Data compression: Reducing the number of features in a dataset with techniques like PCA (Principal Component Analysis).
Popular Algorithms:
- K-means Clustering
- Hierarchical Clustering
- Principal Component Analysis (PCA)
- Autoencoders (for compressing data)
Strengths:
- No labeled data needed, which saves time and cost.
- Great for exploring data, discovering natural groupings or outliers.
Weaknesses:
- Hard to evaluate, since there’s no “correct” answer.
- Results can be confusing or arbitrary if the patterns aren’t obvious.
3. Semi-Supervised Learning: Best of Both Worlds
Definition:
Semi-supervised learning balances between supervised and unsupervised. It uses a small amount of labeled data, just enough to guide learning, and a lot of unlabeled data. Think of it like learning a language from both textbooks (where you have translations) and immersion (just listening and picking things up).
How it Works:
Suppose you have 1,000 labeled images and 10,000 unlabeled ones. A semi-supervised model first learns from the labeled pictures, then refines its understanding with the unlabeled ones, improving its generalization with less manual labeling effort.
Common Examples:
- Text classification: Classifying millions of documents where only some are labeled.
- Image recognition: Training on a few labeled photos plus a large set of unlabeled images.
Popular Algorithms:
- Self-training and pseudo-labeling (the model guesses labels on unlabeled data and retrains)
- MixMatch & FixMatch (modern deep learning for semi-supervised settings)
- Graph-based methods
Strengths:
- Requires much less labeled data than supervised learning.
- Can approach supervised performance at a fraction of the labeling cost.
Weaknesses:
- Trickier to implement and tune.
- Relies on some initial labeled data and assumptions about unlabeled data.
4. Reinforcement Learning: Learning by Trial and Error
Definition:
Reinforcement learning (RL) is like training a dog to do tricks. The “agent” (dog) takes actions in an environment (“sit,” “fetch”), gets rewards or penalties (treats or “no!”), and learns to maximize good outcomes over time.
How it Works:
An RL agent interacts with its environment, making decisions step by step. Every action earns a reward (good or bad). Over thousands or millions of trials, the agent learns a sequence of actions that lead to the highest rewards.
Common Examples:
- Game-playing AI: AlphaGo, AlphaStar, or OpenAI’s Dota bot (OpenAI Five)
- Robotics: Teaching robots to walk, pick up objects, or drive.
- Personalized recommendations: Learning what to show users based on their interactions.
Popular Algorithms:
- Q-learning
- Deep Q Networks (DQN)
- Policy Gradient Methods (e.g., REINFORCE, PPO, A3C) (see Sutton & Barto textbook)
Strengths:
- Excels in sequential decision-making: When actions affect future rewards.
- Adapts dynamically to changing environments.
Weaknesses:
- Data and compute hungry: Needs lots of trials.
- Reward design is tricky: Poorly designed rewards can lead to strange or harmful behaviors.
Choosing the Right Approach: How Do You Decide?
Picking the best learning type is all about your data and your goals:
- Is your data labeled? Choose supervised for accuracy, semi-supervised if you don’t have much labeled data.
- Are you exploring, not predicting? Try unsupervised.
- Want an agent that learns from experience? Go for reinforcement learning.
Each method unlocks different possibilities, and sometimes they’re even used together in large systems.
Quick Cheat Sheet
| Learning Type | Needs Labels? | Best For | Example |
|---|---|---|---|
| Supervised | Yes | Prediction, classification | Email spam filtering |
| Unsupervised | No | Data exploration, clustering | Market segmentation |
| Semi-supervised | Few | When labels are costly | Image recognition |
| Reinforcement | No (but needs explicit feedback) | Sequential decision-making | Game AI, robotics |
Wrapping Up
Mastering machine learning means understanding these core learning styles and knowing which fits your problem and dataset.
As Dr. Andrew Ng famously notes, “Supervised learning currently powers most production ML systems,” but other paradigms are unlocking new potential across technology, science, and business (Stanford CS229 notes).
So next time you face a dataset, ask yourself: What kind of learning does it want? You’ll be on your way to building smarter, more effective machine learning solutions.
Curious to dive deeper? Check out:
- Elements of Statistical Learning
- Reinforcement Learning: An Introduction
- scikit-learn: Supervised and Unsupervised Algorithms
Happy learning!

Leave a comment