
In the first article, I focused on how a data science repository is structured and why that structure supports MLOps practices like repeatability, traceability, and safe iteration. In this follow-on post, I want to zoom in on the machine learning problem itself: the classification task implemented in the repository.
The goal here is not to showcase a clever model or squeeze out incremental accuracy gains. Instead, the repository demonstrates how a classification problem can be implemented in a way that remains understandable, extensible, and production-oriented from the start. The model is important, but it is never treated as the system. The pipeline is.
Defining the Classification Problem
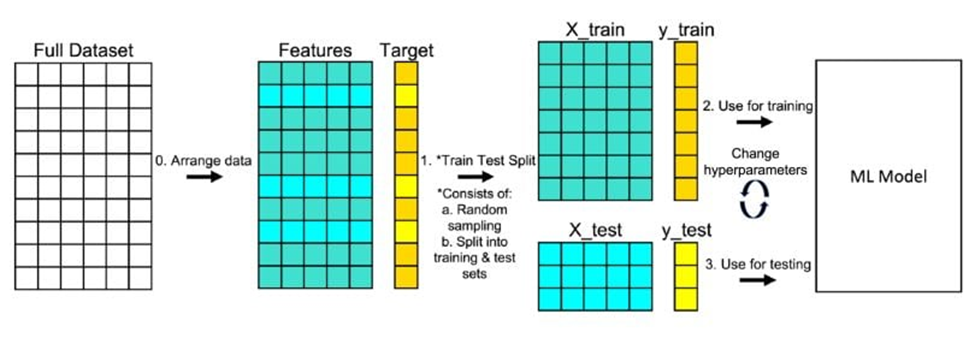
At a high level, the repository implements a supervised classification workflow: features are derived from input data, a model is trained to predict discrete labels, and results are evaluated using consistent metrics. The scope is intentionally modest. This keeps the focus on how the problem is approached rather than on domain complexity.
You can see this framing reflected early in the codebase. The project does not embed assumptions about the data directly into training logic. Instead, responsibilities are separated so that data handling, modeling, and evaluation evolve independently. That separation is what allows the same pattern to scale beyond this example.
Data Ingestion and Preparation
Data handling is one of the easiest places for machine learning projects to become brittle. In this repository, data ingestion and preparation are treated as first-class concerns rather than incidental steps.
The logic for loading and preparing the dataset lives outside of the model code, making the data flow explicit and repeatable. Train/test splits are deterministic, and preprocessing steps are applied consistently across runs. This design ensures that changes to feature engineering do not silently invalidate prior results.
The intent is clear: if you cannot explain how the data moved through the system, you should not trust the model that came out the other side.
Establishing a Baseline Model
Rather than starting with complexity, the repository establishes a simple and interpretable baseline. The model choice is less important than the role it plays: providing a stable reference point against which future changes can be measured.
This philosophy shows up in the training code, where model construction is isolated and parameterized rather than hard-coded. By keeping the baseline straightforward, the repository makes it easy to answer foundational questions early: whether the features contain signal, whether the labels are learnable, and whether the evaluation metrics behave as expected.
A baseline is not a compromise, it is a control.
Training as a Repeatable Experiment
Training in this repository is treated as an executable process, not an interactive exploration. Hyperparameters are explicit, training logic is centralized, and runs are designed to be repeatable.
This distinction matters. When training code is deterministic and well-scoped, it becomes much easier to integrate with automation later, whether that means CI pipelines, experiment tracking, or scheduled retraining. Even without those tools in place, the repository is already structured as if they were coming next.
In practice, this turns model training into something closer to running a build than executing a notebook cell.
Evaluation Beyond a Single Metric
Evaluation is where many example repositories fall short, but here it is handled with care. Rather than relying solely on accuracy, the evaluation logic supports multiple metrics and produces results in a consistent format.
This approach acknowledges a reality of classification work: no single metric tells the full story. Precision, recall, and F1 scores often surface weaknesses that accuracy hides, especially when classes are imbalanced or decision thresholds matter.
By centralizing evaluation, the repository ensures that comparisons between models are meaningful. Every experiment is judged by the same yardstick, which makes iteration safer and more honest.
The latest notebook aggregates the most recent run per experiment and ranks by macro-F1 (tie-breaker: accuracy).
Overall test metrics (latest run per experiment)
| experiment | run_id | test accuracy | test macro-F1 |
|---|---|---|---|
| distilbert_two_phase | 20251223T165758Z | 0.7124 | 0.6183 |
| distilbert_unfrozen | 20251223T010101Z | 0.7069 | 0.6048 |
| tfidf_logreg | 20251222T183959Z | 0.6221 | 0.4909 |
| distilbert_frozen | 20251222T190244Z | 0.5650 | 0.3941 |
| tfidf_dense | 20251222T184926Z | 0.5221 | 0.3370 |
Best model summary (DistilBERT two-phase)
- Accuracy: 0.7124
- Macro-F1: 0.6183
- Weighted-F1: 0.7066
- Classes: 41
- Test examples: 20,086
For the best model, the strongest categories by F1 include:
| class | F1 | support |
|---|---|---|
| STYLE & BEAUTY | 0.8718 | 965 |
| TRAVEL | 0.8394 | 989 |
| HOME & LIVING | 0.8350 | 420 |
| WEDDINGS | 0.8288 | 365 |
| POLITICS | 0.8241 | 3,274 |
| DIVORCE | 0.8208 | 343 |
| SPORTS | 0.7942 | 488 |
| FOOD & DRINK | 0.7891 | 623 |
Harder categories by F1 include:
| class | F1 | support |
|---|---|---|
| GOOD NEWS | 0.3408 | 140 |
| WORLD NEWS | 0.3696 | 218 |
| ARTS | 0.4014 | 151 |
| IMPACT | 0.4628 | 346 |
| PARENTS | 0.4653 | 395 |
| WOMEN | 0.4682 | 349 |
| COLLEGE | 0.4701 | 114 |
| CULTURE & ARTS | 0.4712 | 103 |
Learning From Errors, Not Just Scores
Because predictions, labels, and metrics are produced consistently, error analysis becomes a natural extension of the workflow rather than a manual exercise. Misclassifications can be inspected, patterns can be identified, and improvements can be targeted without refactoring large portions of code.
This is where structure quietly pays off. When responsibilities are well defined, learning from mistakes does not require unraveling the system. It simply requires asking better questions of the outputs.
Scaling the Pattern
The most important thing this repository demonstrates is not how to solve a specific classification problem, but how to structure one so it can evolve. New datasets can be introduced. Features can be added. Models can be swapped. The surrounding workflow remains intact.
That is the real lesson. Classification problems change. Good patterns endure.
Closing Thoughts
This repository treats classification as a system rather than an artifact. The model is only one component in a pipeline designed for clarity, repeatability, and growth.
If the first article was about how the repository is organized, this one is about why that organization matters when you start making predictions. Together, they tell a more complete story: one where machine learning work is engineered to last, not just to run.

Leave a comment